5 Elements of a Data Migration Project

Now that you have decided to take on a data migration project as part of your tech stack consolidation effort, and thought through how to prepare for the initiative, let’s talk about what the actual data migration process entails. Note again that data migration is often only one piece of a comprehensive tech stack consolidation effort.
There are four foundational elements to every data migration effort:
For some companies, a data migration project into a target Salesforce instance is all that is required (i.e. the acquired company shares a similar process as the acquiring company, or the acquired team will conform to the process of the acquiring company.) However, if you are seeking to true up the difference between different processes, build a newer and better set of processes for all teams involved, or accommodate multiple ways of handling business in one Salesforce instance, we’re talking about a full blown tech stack consolidation project. Sometimes, your company is on such a growth spurt that you’re looking at multiple sets of data at a time, as in the case of multiple acquisitions. You’ll want experienced experts on your team. OpFocus’ team of business growth experts stand at the ready to help. We’ve overseen dozens of mergers and migrations, and can help you avoid the pitfalls.
#1 System Configuration
When you begin your data migration project, the first step is configuring the system. To start, you’ll want to assess the architecture of the receiving Salesforce instance, which involves reviewing the Objects in use, Record Types, Page Layouts, Validation Rules, the data structure of the migrating system, and whether the migrating system is a Salesforce instance or other structured database.
In addition to conducting an inventory of Fields and Objects, reviewing overall security, strategy, and policies is essential during this phase. For data security, Salesforce provides great visual content to better understand its data model.
As an overview, there are 3 basic structures to how Salesforce stores data:
- Objects (i.e. tables within a database) – controlled by “Profiles” and “Permission Sets”
- Fields (i.e. columns within a table) – controlled by “Field-level Security”
- Records (i.e. rows within a table) – controlled by “Sharing Rules” and the “Role Hierarchy”
To complete the data mapping portion of the project, review each level of the data model for each system, and then compare/contrast where the data access is different. Your data migration team will need to thoroughly understand the visibility of the components above, and determine which dataset requires transformation to fit into the other system’s data structure.
Here is another way to understand the different layers of the onion.
Salesforce Data Visibility Circle
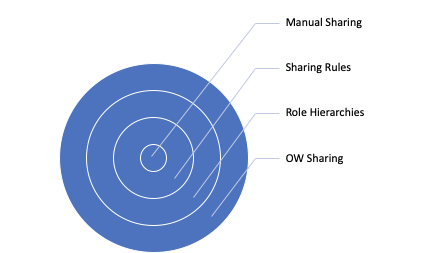
Once this work is complete, you should have a solid understanding of the types & format of data you’re working with. This will also give you the opportunity to decide how to set up security and permissions in the combined tech stack. Once completed, it’s time to review your Tech Stack & Custom Integrations.
#2 Integrated Tools
After determining the delta between the two data structures, you’ll want to look at external apps that write or read data in your system. Start by creating an inventory of all the applications and Managed Packages that make up your tech stack. This inventory should capture all the tools your team is actively using, and validate whether you plan to bring those same tools and integrations over to the target system.
During an engagement with OpFocus, we will make recommendations to consolidate and retire certain items in pursuit of a streamlined, non-duplicative tech stack. You may want to create an Excel/Google Sheet with labels for each “product,” “install date,” “current version,”and “comments” for how each team is using each tool. You’ll also want to consider whether it is necessary to maintain those tools and integrations as part of the migration.
Key questions to understand the tools in each system
- What apps or system integrations exist in the retiring organization that are needed but not in the surviving organization?
- What tools should we retire?
- What tools should we keep? Which tools will require new User licenses?
- Will the 3rd party app automatically port over data to the new system when we turn on the new integration? Or will we need to manually migrate data over?
- What other system dependencies exist?
*There could be scenarios where we are unable to migrate all data due to limitations with the Managed Package. It is critical to understand the limitations early on in the process.*
There are many resources online for the analysis of your tech stack. Even a Google Sheet or Excel file to track the dependencies would work if your systems aren’t overly complex. However, visualizations are a great way to help your stakeholders understand the interdependence of the tools. Cisco and Scott Brinker have done a great job sharing their methodology. Image and link to their blog is below:
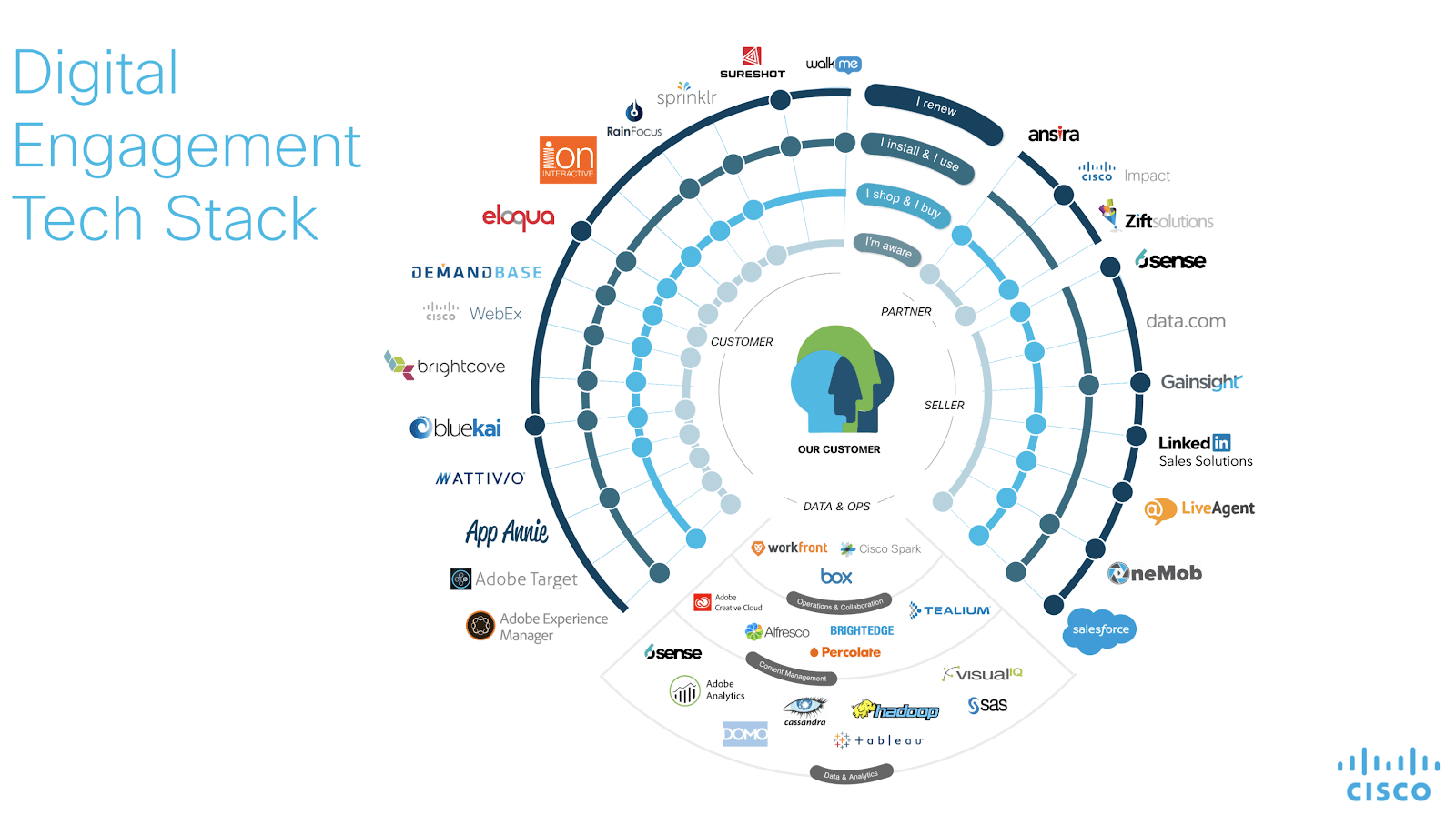
After this assessment, your team will have a complete inventory of the tools that make up your tech stacks. This information will prove useful when you arrive at the decision of determining which tools to carry over to the new tech stack and which to retire. After this evaluation is completed, you’re ready to move on to the State of the Data portion of the data migration project.
#3 State of the Data
You’re now ready to evaluate the current state of your data. This process involves the actual records that are in the system we are extracting from, and can come from systems like Salesforce, Pardot, Hubspot, Marketo, Dynamics 365, or even a custom CRM! Each of these systems have different data structures, data types, and naming conventions. Depending on where it’s stored and how it’s stored, the process can be more or less challenging.
Key questions to assess the current state of your data:
- What is your Data Governance Policy?
- Are there any tools leveraged for data governance efforts?
- Is there an owner in place?
- What are the deduplicate tools being used? If there are none, what is the rationale?
- Are there controls in place to prevent duplications? Are these controls in place prior to creating the record?
- Who are the users entering the data?
- How are well are users and admins using these data tools?
- Is there any custom development that is updating fields/creating new data? (Often times, we encounter “worst” practice configuration or development issues that have been plaguing a client’s instance for years. This is a prime opportunity to sort out those issues and reduce ongoing maintenance costs.)
- What is the completeness of data? (Tools like “Field Dumper” help determine how frequently users are populating data in fields within Page Layouts)
Object Design
When thinking about the data, it’s important to understand how your objects have been set up. This analysis takes a slightly different perspective than the process we described in the data visibility section.The point of the object design review is to raise awareness around the structure/data design.
Some of these design aspects are:
- Record Types of the target and migrating org
- Objects the data is coming from (characteristics of these objects is key)
- For example, if you are importing object data that does not exist in the target org, will you create a net new Custom Object?
- Typically you would want to create a new Object, unless the design is straightforward enough and you can simply configure new Record Types on existing Objects
You are only as efficient and as good as your data. This step is critical in enabling your Users to have data that is easy to understand & work with in the target system. Failure to do so results in a lot of User frustration. Some examples we’ve heard include Users asking, “Why is this missing?” “This field used to have data.” “Why is _____ data missing from my Opportunity records?”
#4 Data Cleanliness
Understanding & cleaning your data is a collaborative effort. This step of the process is a great time to understand what has historically made your system data inaccurate or error prone.
4 Steps for Data Cleansing:
- Create a standardized process for your respective business units
- Backfill missing data
- Validate data accuracy
- Remove and merge the duplicate data
As we like to say: fix bad data today! For more trustworthy and dependable data, build in parameters within Salesforce to prevent duplicates and poor data quality. Properly deployed, Validation Rules and Required Fields on the Page Layout (we don’t recommend universally requiring a field unless absolutely necessary.. and times are few and far between) will save you data headaches down the road. Once your database is clean and you’ve set up your target org for data success, you’re ready to begin the process of Data Mapping.
#5 Data Mapping
At this point, you are well on your way to completing your data migration project! The next step is data mapping, which will require the most active involvement from your stakeholders. Even though this is #5 on our list, we typically start this process on day one due to how labor intensive this process is.
In short, data mapping is the process of taking inventory of all system fields and making decisions on how those Fields will be named and behave in the new environment.
Data mapping helps to determine what Fields are the same between the two (or more) org(s), which Fields are different, and the specific values within the Fields. If you’re working on a project with OpFocus, we will provide worksheets that help your team review and consider the future state of all Fields, and to ensure that your key business processes and metrics are available once the consolidated tech stack goes live.
Mapping Tool Checklist
When mapping the data, you can decide between using more simplistic tools such as Excel to do a database extract or sophisticated (paid) tools. Which approach should you take? These questions will help you determine the best path forward:
- How important is Drag and Drop field mapping to your team?
- Are your business users comfortable interacting with databases, or would you prefer for them to interact with a graphic interface?
- Do you want a cloud-based web UI?
- How would you like your error log presented when there are issues with validation?
- Would it help to preview transformation results inside a map?
- Does your migration need to work with files that are larger than 5MB?
- Are you migrating multiple sources of data, and want to see how all systems map to the target system?
- Do you need to run Java inside a map?
- Do you need to run SQL and stored procedures inside a map?
- Do you need to make database calls inside a map?
- Do you need to support many data formats, such as XML, Database, Cloud Apps, ERP, CRM, CSV, Excel or others?
- How helpful is conditional and rules-based mapping?
- Would it help to auto-generate a Mapping Document in PDF for other business stakeholders?
- Would you need value maps for cross-reference lookups?
Once you have determined your needs for the mapping, you can think about the 2 options we mentioned above. There are Excel templates out there for data mapping, or you can create your own. As far as purchased tools go, we have used a number that worked for different customers’ needs, including:
- Alooma (Part of Google cloud)
- Informatica
- Liquid Technologies
- Salesforce Schema Lister (exports a schema from your Salesforce instance, builds a list of objects, fields and attributes)
Needless to say, using a tool can help simplify the process of data mapping when working with more complex organizations.
During data mapping, there are 5 steps per object you’ll want to create columns/sections for:
- Required Fields
- Optional Fields
- System Generated Fields (do you want to include these fields as new fields in the destination org?)
- Legacy IDs (Old Salesforce IDs)
- 15-character IDs generated from a Salesforce report are not unique when using a vLookup function. Create 18-character key using the CASESAFEID formula for an export and create Legacy ID fields for each object
- History Tables
- Stage History for Opportunities / Case History for cases cannot be migrated. DO we need a custom object to track these pieces or is the current Stage/Case History sufficient?
Final Thoughts
Data mapping is one of the most important aspects of the Data Migration process and will set the foundation for your new organization to build off of. Ensuring your data is cleansed and mapped appropriately will provide a clean environment for your new organization. If you need help with any of these elements, reach out to our Tech Stack Consolidation experts to chat about how we can support this critical initiative. We’ve worked with many rapid-growing SaaS teams and can help you avoid pitfalls with these complex projects!



